Introduction
Ever tried printing special characters like “¡Hola!” or “नमस्ते” in Python and seen strange symbols instead? You’re not alone. Text encoding issues often confuse beginners — but mastering them is essential for working with global data.
In this guide, we’ll break down how the python encode string method works, why encoding matters in real-world applications, and how you can confidently handle Unicode and text encoding in any project.
By the end, you’ll understand what encoding actually means, how to choose the right encoding type, and how to fix common encoding errors in Python that is python encode string— all explained step by step with code examples.
What Is String Encoding in Python?
String encoding is the process of converting human-readable text (Unicode) into machine-readable bytes.
Python internally stores strings as Unicode, but to save or transmit data (like writing to a file or sending over a network), we need to encode that Unicode text into a specific byte format — like UTF-8 or ASCII.
In short:
Encoding = Unicode → Bytes
Decoding = Bytes → Unicode
How encode() Works in Python
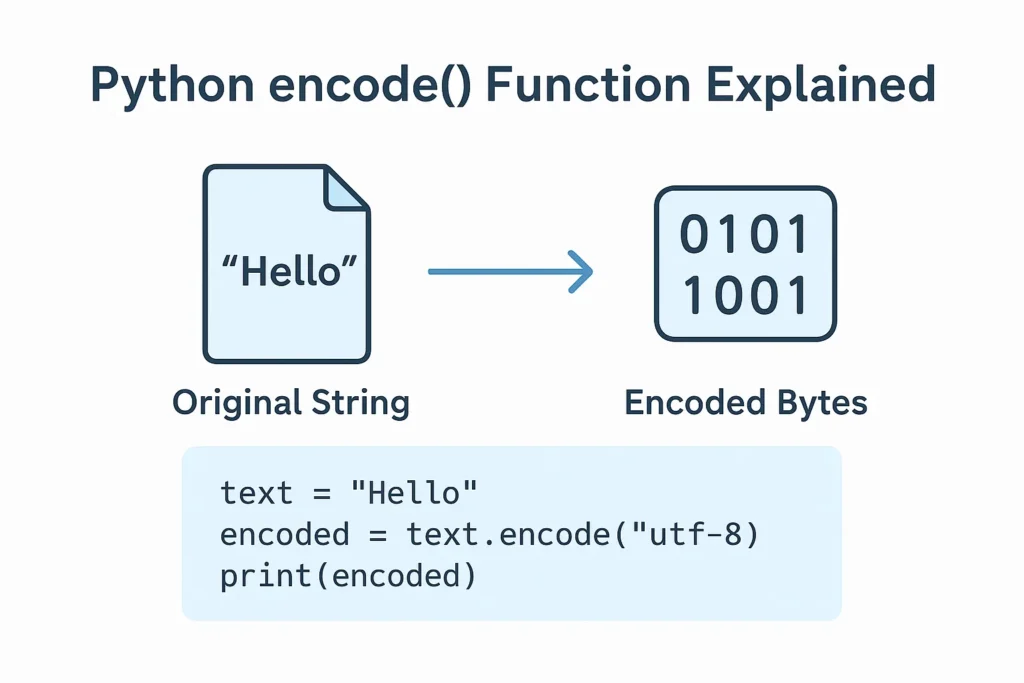
Python provides the str.encode() method to convert strings into bytes using a specific encoding format.
Syntax:
string.encode(encoding="utf-8", errors="strict")Parameters:
- encoding: Name of the character encoding (e.g.,
"utf-8","ascii","utf-16"). - errors: How to handle errors if a character can’t be encoded.
- Options include:
"strict"– Raise an error (default)"ignore"– Skip characters that can’t be encoded"replace"– Replace unencodable characters with?
Example:
text = "Python 🐍"
encoded_text = text.encode("utf-8")
print(encoded_text)Output:
b'Python \xf0\x9f\x90\x8d'Here, b'' indicates a byte object, and the emoji 🐍 is encoded into UTF-8 bytes.
Encoding Examples in Python
Let’s explore a few real-world examples of python encode string in action.
1.Encoding in UTF-8
text = "Café"
utf8_encoded = text.encode("utf-8")
print(utf8_encoded)Output:
b'Caf\xc3\xa9'UTF-8 successfully encodes the accented “é”.
2.Encoding in ASCII (with replacement)
ascii_encoded = text.encode("ascii", errors="replace")
print(ascii_encoded)Output:
b'Caf?'ASCII can’t handle accented letters, so it replaces them with ?.
3.Encoding and Decoding Back
decoded_text = utf8_encoded.decode("utf-8")
print(decoded_text)Output:
CaféYou can easily convert bytes back to string using .decode().
Common Encoding Types Explained
Here’s a quick comparison of popular encodings:
| Encoding | Description | Supports Special Characters? | Bytes Used |
|---|---|---|---|
| ASCII | Basic Latin characters only | ❌ | 1 byte per char |
| UTF-8 | Universal standard; backward compatible with ASCII | ✅ | 1–4 bytes |
| UTF-16 | Unicode encoding using 2–4 bytes | ✅ | 2+ bytes |
| ISO-8859-1 | Western Europe encoding | ⚠️ Partial | 1 byte |
Recommendation: Always use UTF-8 — it’s the global standard and works across all platforms.
Real-World Analogy: Translating Languages
Think of text encoding as translating a message between two languages of python encode string():
- The original text is in your native language (Unicode).
- Encoding translates it into a code (bytes) that computers can understand.
- Decoding translates it back to your language (text).
If you use the wrong “language” (encoding type), the translation will break — leading to weird symbols or “mojibake” errors like é instead of é.
This is exactly what happens when files are read using the wrong encoding format.
Tips, Tricks, and Common Mistakes
Here are some practical lessons from real-world projects (including my experience handling multilingual CSV files in Python):
Best Practices
Always specify encoding explicitly when reading/writing files:
open("data.txt", "w", encoding="utf-8")Use UTF-8 everywhere unless you have a specific reason not to.
Check a file’s encoding using tools like chardet or file command (Linux).
Common Mistakes
- Forgetting to specify encoding
- Default system encoding can differ (Windows vs Linux), leading to bugs.
- Using ASCII for non-English data
- Causes
UnicodeEncodeError: 'ascii' codec can't encode character.
- Causes
- Double-encoding text
- Avoid doing
.encode().encode()— once is enough!
- Avoid doing
FAQs / Interview Questions
1. What does encode() do in Python?
It converts a Unicode string into a bytes object using a specific encoding like UTF-8 or ASCII.
2. What’s the difference between encode() and decode()?
encode()→ Converts string to bytesdecode()→ Converts bytes back to string
3. Why do we get a UnicodeEncodeError?
You’ll see this when Python tries to encode characters not supported by the chosen encoding (e.g., using ASCII for emojis).
4. How do I fix “UnicodeDecodeError: ‘utf-8’ codec can’t decode byte”?
Try specifying the correct encoding when reading the file, e.g.:
open("file.txt", "r", encoding="latin-1")Conclusion and Next Steps
Encoding is one of those invisible layers in programming — you don’t think about it until something breaks. But understanding how Python encode string works gives you control over your data, especially when handling multilingual or binary files.
Here’s what you’ve learned:
- What encoding is and why it matters
- How to use
str.encode()andbytes.decode() - The difference between UTF-8, ASCII, and UTF-16
- How to fix and prevent encoding-related errors
More Tutorials
please visit the blow tutorial was already the
Python List Tutorial for Beginners
Master the Top Python List Methods
Slicing and Nested Lists
If you want the more Knowledge on this tutorials then check below tutorial
Python String encode()
Unicode HOWTO
Over to you!
Have you faced weird text encoding issues before? Drop your experience or questions in the comments — and don’t forget to subscribe to vbkinfo.xyz for more practical Python tutorials.
Author Bio
Written by Vaibhav B. Kurale for vbkinfo.xyz – I love simplifying Python and technology concepts for learners.
I enjoy turning complex coding topics into easy, beginner-friendly explanations.
My goal is to make learning practical, clear, and enjoyable for everyone.
Through vbkinfo.xyz